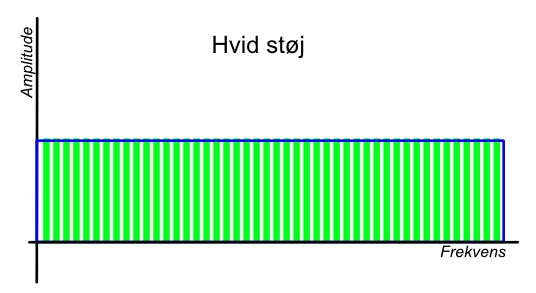
Hvis man laver et histogram over en mængde tilfældige hændelser, vil der fremkomme en kontur af grafikken. Er hændelserne fuldstændigt tilfældige, får man en figur, der begynder og slutter brat, og har en helt lige top, fordi alle resultaterne har samme sandsynlighed for at indtræffe, og man har en såkaldt ‘rektangulær fordeling’. F.eks. har lydbegrebet ‘hvid støj’ en rektangulær fordeling af frekvensindhold, for alle frekvenser optræder lige hyppigt og i samme omfang. Men rigtig ofte ligner histogrammets kontur en klokke, og så har man fat i en normalfordeling.
Der er flere typer fordelinger, men de er ikke relevante her. Der skelnes også mellem diskrete og kontinuerte hændelser, men det er heller ikke noget, vi dykker ned i.
Wikipedia beskriver normalfordelingen således:
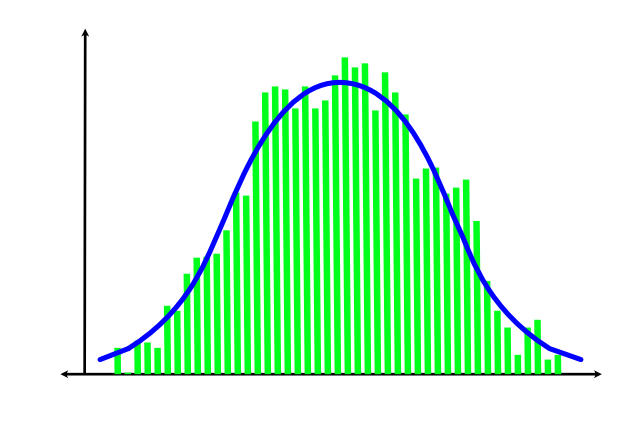
“Hvad normalt er der ved normalfordelingen? Teoretisk adskiller normalfordelingen sig fra andre sandsynlighedsfordelinger ved sin rolle i den centrale grænseværdisætning. Meget populært udtrykt siger denne sætning, at en størrelse der fremkommer som resultatet af mange små tilfældige og uafhængige bidrag, vil være (tilnærmelsesvis) normalfordelt. Dette giver en teoretisk “begrundelse” for hvorfor netop denne fordeling ofte er brugbar i praktiske anvendelser.”
Den fortæller altså, at hvis man har mange tilfældige hændelser (som de mange vidt forskellige individer, der kommer i en kommunes genoptræning) vil de være normalfordelt. Normalfordelingsfunktionen ligner en klokke, når man tegner den. Derfor kaldes den også klokkefunktionen. Den kaldes også Gaussfordelingen efter den legendariske matematiker, der kom med formlen for funktionen.
Det interessante i forhold til denne side er, at den visualiserer problemet ved at bruge baggrundsviden frem for reel, nutidig og særligt individuel viden.
En normalfordeling kan beskrives alene med middelværdien (toppunktet, μ), og spredningen (σ). Det vil altid forholde sig sådan, at 68,2 % af tilfældene vil være inden for gennemsnittet +/- en spredning. Næsten en tredjedel, vil falde udenfor.
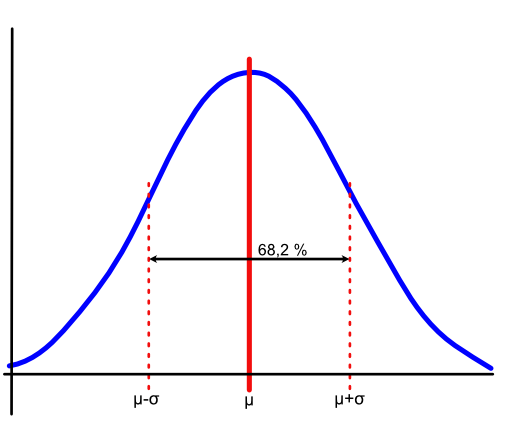
Det vil altså betyde, at hvis der kommer tilstrækkeligt mange ramte til et genoptræningssted, vil 68,2 % opføre sig omtrent som gennemsnittet, mens resten ikke har den store effekt af genoptræning ud fra gennemsnitsmodellen. Dette her er et indiskutabelt matematisk faktum, uanset hvad terapeuterne og deres underviseres erfaringer bilder dem ind. Den sidste tredjedel vil være anderledes i deres læringsstil, eller deres historik, eller deres motivation, eller alle deres tabte kampe med “systemet der ved alt”, eller … De vil bare være anderledes nok til, at man ikke får et særligt godt resultat ud af, at gøre som man plejer. Altså basere sig på baggrundsviden fremfor reelt observeret, lyttet og målt viden.
Det er ikke umuligt, at kurven er meget snæver, dvs. lav spredning, men det ville betyde, at alle individer reagerede stort set ens (gennemsnitligt normalt) på terapien. Men jeg tror, at det er meget mere sandsynligt, at en tredjedel modtager en stort set nytteløs træning (og regn lige på, hvad det koster). Det ville være rart, hvis en eller anden kommune har data på dette her, som vi kan analysere.